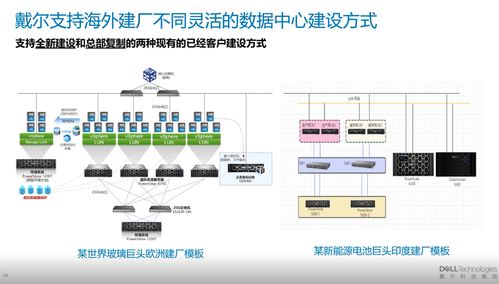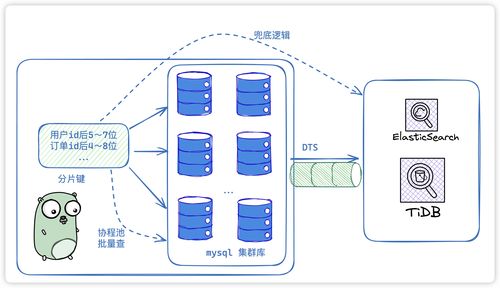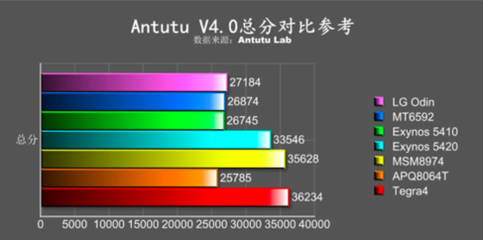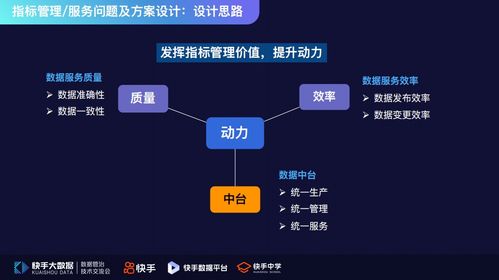
在当今数据爆炸的时代,如何高效处理海量、多样、高速的数据成为企业和技术人员面临的核心挑战。Hadoop作为大数据处理领域最著名、最成熟的开源框架,自诞生以来,便以其分布式、可扩展、高容错的特性,构建了现代大数据处理的基石。其数据处理能力,特别是通过其核心组件MapReduce和YARN,定义了一个经典且强大的数据处理范式。
一、Hadoop生态系统概述
Hadoop并非单一软件,而是一个由多个相关项目构成的生态系统。其核心是Hadoop Common(公共模块)、Hadoop Distributed File System (HDFS) 和 Hadoop YARN。
- HDFS:是Hadoop的存储基础。它将大文件切分成固定大小的数据块(Block),并分布式地存储在集群的多个节点上,同时通过多副本机制实现高容错性和高可用性。其“一次写入,多次读取”的模型非常适合大数据批处理场景。
- YARN:是Hadoop 2.0引入的资源管理和作业调度平台。它将资源管理与具体的计算框架解耦,使得Hadoop集群能够同时运行MapReduce、Spark、Flink等多种计算框架,极大地提升了集群的资源利用率和灵活性。
二、核心数据处理范式:MapReduce
MapReduce是Hadoop最初的数据处理引擎,其编程模型简单而强大,将复杂的数据处理任务分解为两个主要阶段:
- Map阶段:由多个Map任务并行执行。每个任务读取输入数据的一个分片(Split,通常对应HDFS的一个数据块),执行用户定义的
map()函数,将输入键值对转换为一系列中间键值对。这个过程是“分而治之”的体现。 - Shuffle与Sort阶段:这是框架自动完成的“幕后英雄”。系统会将所有Map任务产生的中间结果,根据键(Key)进行分区、排序和合并,然后分发给相应的Reduce任务。这个阶段是网络数据传输最密集的部分,也是性能优化的关键点之一。
- Reduce阶段:由多个Reduce任务并行执行。每个Reduce任务接收属于自己分区的、已经排序的中间键值对,执行用户定义的
reduce()函数,对具有相同键的值进行聚合、计算,最终产生输出结果,并写入HDFS。
经典应用:词频统计(WordCount)是理解MapReduce的最佳入门案例。Map任务将文档拆分成单词并输出 <单词, 1>,Shuffle阶段将相同单词聚集到一起,Reduce任务则对每个单词的“1”列表进行求和,得到每个单词的总出现次数。
三、数据处理的优势与挑战
优势:
1. 高可扩展性:通过简单增加廉价的商用服务器(节点)即可线性扩展存储和计算能力。
2. 高容错性:数据在HDFS上有多个副本,计算任务失败后可由YARN在其它节点上重新调度执行。
3. 成本效益:基于开源软件和通用硬件,构建大规模集群的成本远低于传统大型机和高端存储。
4. 适合批处理:对TB/PB级别的历史数据进行离线分析、数据挖掘、日志处理等场景优势明显。
挑战与演进:
1. 延迟高:MapReduce的中间结果需要写磁盘,且任务调度开销大,导致处理延迟通常在分钟甚至小时级,不适合实时或交互式查询。
2. 编程模型相对固定:复杂的多阶段计算需要串联多个MapReduce作业,开发效率较低。
3. 生态系统演进:正因为这些挑战,以Spark为代表的新一代内存计算框架迅速崛起。Spark基于RDD/DataFrame模型,通过内存计算和更丰富的算子( transformations和actions),在保持容错性的将处理速度提升了数十倍到百倍,并更好地支持流处理、机器学习和图计算。如今,Spark常运行在由YARN管理的Hadoop集群上,复用HDFS进行存储,形成了优势互补的架构。
四、现代Hadoop数据处理架构
一个典型的现代大数据处理平台往往采用分层架构:
- 存储层:以HDFS为核心,可能结合对象存储(如S3)或NoSQL数据库(如HBase)。
- 资源管理层:由YARN统一调度集群的CPU、内存等资源。
- 计算引擎层:根据场景选择不同引擎。批处理可选用MapReduce或Spark;交互式查询可选用Hive(将SQL转化为MapReduce/Spark任务)或Impala/Presto;流处理可选用Spark Streaming或Flink;机器学习可选用Spark MLlib。
- 数据管理与服务层:包括元数据管理(Hive Metastore)、工作流调度(Azkaban, Oozie)、数据集成(Sqoop, Flume)等。
结论
Hadoop开启了大数据的工业化处理时代。尽管其原生的MapReduce引擎在实时性上已非首选,但HDFS和YARN构成的稳定、可靠的存储与资源管理底座,依然是众多企业大数据平台的基石。理解Hadoop的数据处理架构——从HDFS的分布式存储,到MapReduce的批处理模型,再到YARN的资源统一管理——是深入大数据技术领域的必经之路。今天,我们更应将其视为一个强大的生态基石,在其之上灵活选用Spark、Flink等更高效的计算引擎,共同构建满足多样化需求的数据处理解决方案。