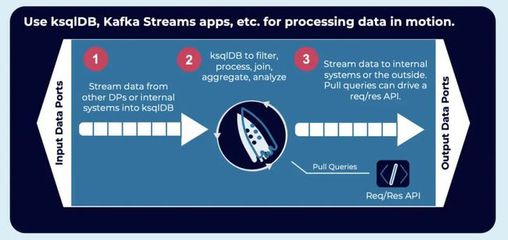
在现代数据驱动型应用中,实时数据交换与处理能力已成为核心竞争力。Apache Kafka作为分布式事件流平台,与动态数据网格(Dynamic Data Grid)的结合,为构建高性能、可扩展、低延迟的流式数据处理架构提供了强大支撑。
一、核心组件:Kafka与动态数据网格
Apache Kafka是一个高吞吐量、可水平扩展的分布式发布-订阅消息系统。它通过主题(Topic)组织数据流,生产者(Producer)将数据发布到主题,消费者(Consumer)从主题订阅并处理数据。其持久化日志、分区机制和副本策略确保了数据的可靠性和有序性。
动态数据网格(通常以Hazelcast、Apache Ignite等内存数据网格为代表)是一种分布式内存计算和存储层。它将数据存储在集群节点的内存中,提供极低延迟的数据访问,并支持分布式计算、事件监听、数据分区与复制等功能。其“动态”特性体现在节点可动态加入或离开集群,数据自动重新平衡。
二、架构融合:流式数据交换与处理的协同
典型的整合架构中,Kafka充当统一、可靠的数据流中枢。来自各类源头(如数据库变更日志、应用日志、物联网设备、微服务事件)的数据实时写入Kafka主题。动态数据网格则扮演近数据处理的角色,它可以作为Kafka的消费者,订阅相关主题,将流数据实时加载到内存网格中。
这种模式实现了清晰的责任分离:Kafka负责数据的持久化、有序传输和缓冲;数据网格则提供内存高速访问、复杂事件处理(CEP)、实时查询和状态维护。例如,一个实时风控系统可以将交易事件流通过Kafka传输,数据网格中的计算节点实时消费这些事件,在内存中维护用户画像、交易模式等状态,并即时执行风险规则计算。
三、关键优势与实现模式
- 极致的性能与低延迟:数据网格的内存存储将热数据保持在RAM中,结合Kafka的高吞吐量,使端到端的处理延迟可降至毫秒级。
- 弹性和可扩展性:两者均为分布式设计。Kafka可通过增加分区和代理(Broker)水平扩展吞吐量;数据网格可通过添加节点线性扩展存储与计算能力,并自动处理数据再平衡。
- 状态化流处理:数据网格为流处理提供了分布式、高可用的状态存储。这对于窗口聚合、会话分析、机器学习模型状态等需要维护上下文的应用至关重要。
- 事件驱动与数据本地性:数据网格支持监听其内部数据变更事件。结合Kafka的流输入,可以构建事件驱动架构,并在数据所在的网格节点上直接执行计算,最大化利用数据本地性。
常见的实现模式包括:
- 缓存与物化视图:将Kafka流中的数据实时聚合、转换后存入数据网格,为前端应用提供亚秒级查询响应的物化视图。
- 复杂事件处理引擎:利用数据网格的分布式计算能力,在内存中并行处理多个Kafka事件流,检测复杂模式。
- 微服务状态共享与解耦:多个微服务通过Kafka交换事件,并将共享状态(如用户会话、库存快照)存储在数据网格中,避免服务间紧耦合的直接调用。
四、挑战与最佳实践
尽管优势显著,该架构也带来挑战:
- 架构复杂性:需要运维两个分布式系统,对监控、部署和故障排查要求更高。
- 数据一致性:在分布式环境中,需要仔细设计事务语义和最终一致性模型。可采用Kafka事务API与数据网格的分布式事务或乐观锁结合。
- 内存管理:数据网格容量受物理内存限制,需有选择地存储热数据,并设计数据逐出(Eviction)策略。
最佳实践建议:
- 明确数据生命周期,将Kafka用于长期事件日志存储,数据网格用于实时处理所需的活跃数据集。
- 利用Kafka Connect或自定义消费者,高效地将数据从Kafka加载到数据网格。
- 实施细粒度的监控,涵盖Kafka集群健康(如滞后消费者)、数据网格内存使用、节点状态及端到端延迟。
- 设计容错机制,确保在节点故障时,Kafka的消费位移(Offset)和数据网格的副本能保障处理不中断、数据不丢失。
Kafka与动态数据网格的协同,构建了一个从高效流式数据交换到实时智能处理的完整链路。这种架构完美契合了实时数据分析、实时个性化推荐、物联网监控、金融交易处理等对时效性要求极高的场景。通过合理的设计与运维,组织能够驾驭持续增长的数据洪流,并从中提取即时价值,驱动业务敏捷决策与创新。